
About Data Engineering for AI
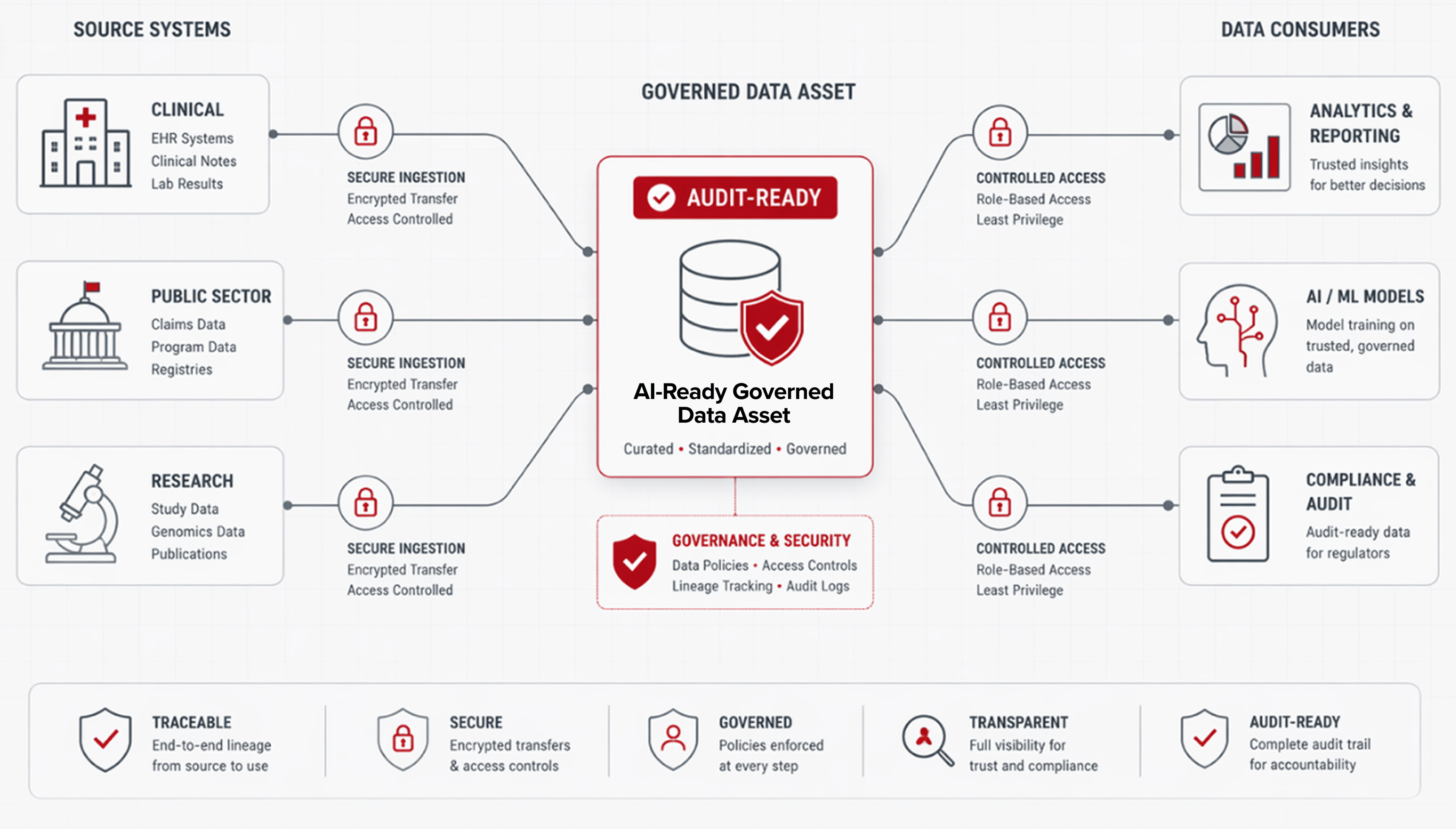
RIT helps research teams and partners prepare data for responsible AI use. AI systems are only as reliable as the quality, scrutiny, and organization of the data that powers them. We build secure data pipelines, clean and standardize complex datasets, support data curation and labeling, and create traceable AI-ready assets that can be used for model development, retrieval-augmented generation, analytics, and work flow automation.
Our team focuses on reputable, governed, and audit-ready methods so data can move from raw source systems into secure environments where it is organized, documented, versioned, and ready for AI-supported work.
Securely transforming source data into trusted, traceable, and audit-ready assets for AI and analytics.
How RIT Prepare Data for AI

Build secure data pipelines
RIT designs automated pathways to extract, ingest, transform, and move data from source systems into approved analysis or AI environments. This may include systems, administrative records, research repositories, state-hosted platforms, private clouds, or secure research enclaves.

Clean, standardize, and model data
RIT prepares raw data for AI by cleaning, structuring, and standardizing it into formats. When appropriate, we support common data models such as OMOP/OHDSI so data can be reused across analytics, cohort discovery, model development, and AI-enabled applications.

Curate and label data for AI use
RIT supports data curation and labeling workflows that combine technical processing with domain expertise. This may include organizing clinical or administrative datasets, validating classifications, preparing training data, and using human-in-the-loop review to improve data quality and reliability.
What RIT Can Build
Unstructured data extraction
RIT helps convert unstructured information into usable data. This may include using natural language, processing, document intelligence, or related methods to extract information from policies, forms, reports, case, notes, clinical documentation, handwritten notes, or other text-based sources.
Knowledge bases for Generative AI
RIT prepare source documents, retrieval corpora, embeddings and knowledge bases for Generative AI and retrieval-augmented generation system. This helps AI tools produce grounded responses based on approved, organized, and traceable source materials.
Synthetic data and secure sandboxes
RIT can help create lower-risk data environments for testing, training, and pilot development. Synthetic data and secure sandboxes allow teams to explore AI workflow without exposing sensitive or regulated information.

Data lineage, quality, and governance
RIT documents where data comes from, how it changes, and how it is used. We support data lineage tracking, quality checks, bias review, version-controlled documentation, data, dictionaries, feature management, and audit-ready records align with high-accountability environments.

Multimodal data integration
RIT supports AI projects that require multiple types of data, including text, documents, clinical records, imaging-adjacent data, omics data, administrative data, and longitudinal research datasets. We help teams connect and organize these sources so they can be used responsibly in AI analytics workflows.